%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Audio processing
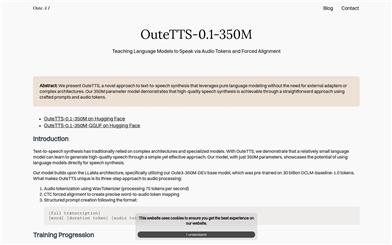
Outetts 0.1 350M
OuteTTS-0.1-350M is a text-to-speech synthesis technology based on a pure language model, requiring no external adapters or complex architectures, achieving high-quality voice synthesis through carefully designed prompts and audio tokenization. This model is based on the LLaMa architecture, utilizing 350 million parameters to demonstrate the potential for direct voice synthesis using language models. It processes audio in three steps: using WavTokenizer for audio tokenization, creating precise word-to-audio mappings through CTC forced alignment, and generating structured prompts that follow specific formats. The key advantages of OuteTTS include a pure language modeling approach, voice cloning capabilities, and compatibility with llama.cpp and GGUF formats.
Text-to-Speech
75.6K
Browser AI Kit
The Browser AI Kit is a platform that integrates various AI tools accessible directly in your browser without installation or setup. It offers functionalities such as audio-to-text, background removal, and text-to-speech, all completely free. This toolkit is developed based on Transformers.js, emphasizing data security and privacy; all data processing occurs locally without uploading to any server. Its goal is to provide users with a convenient, secure, and multifunctional AI tool platform.
Development & Tools
48.3K
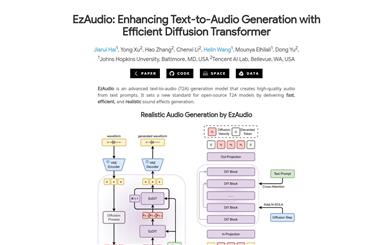
Ezaudio
EzAudio is an advanced text-to-audio (T2A) generation model that can create high-quality audio from text prompts. It sets a new standard for open-source T2A models, delivering fast, efficient, and realistic sound effect generation.
AI text translation and voice
51.6K
Fresh Picks
Qwen2 Audio
Qwen2-Audio is a large audio language model proposed by Alibaba Cloud, capable of processing various audio signals as input and performing audio analysis or direct text reply based on speech commands. The model supports two different audio interaction modes: voice chat and audio analysis. It has achieved outstanding performance in 13 standard benchmark tests, including automatic speech recognition, speech-to-text translation, and speech emotion recognition.
AI Speech Assistant
202.0K
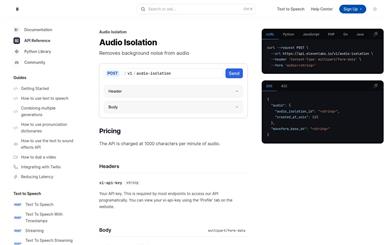
Elevenlabs Audio Isolation API
Audio Isolation is an online audio processing service provided by ElevenLabs, dedicated to segregating vocals or background music from audio tracks. This technology is crucial for applications in music production and post-production video editing, significantly enhancing the efficiency and quality of audio editing. The service is provided via API, supports multiple programming languages, and offers high flexibility and ease of use. Pricing is based on the number of audio characters processed per minute, with specific costs not clearly indicated on the website.
AI Audio Editing
67.6K
Fresh Picks
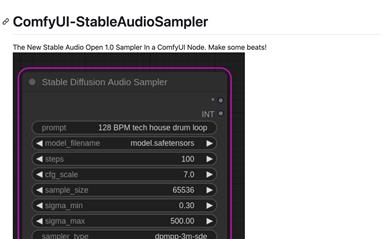
Comfyui StableAudioSampler
ComfyUI-StableAudioSampler is an audio sampler plugin integrated into the ComfyUI node. It allows users to generate audio and output raw bytes and sample rate, supports all original Stable Audio Open parameters, and can save the audio to a file. This plugin is open-source and under active development, aiming to provide music creators with an easy-to-use and powerful tool.
AI music generation
82.8K
Adobe Premiere Pro
Adobe Premiere Pro is a powerful video editing software that integrates AI technology to simplify complex editing tasks and accelerate the editing process. The software provides features such as text-based editing, AI-powered audio classification, speech-to-text, voice enhancement, scene detection, auto-color adjustment, shape transformation, color matching, automatic audio adjustment, and automatic reconstruction, significantly improving editing efficiency and creative possibilities. Premiere Pro is suitable for editing everything from social media short videos to feature films, helping users save time and focus on creativity and storytelling. Later this year, Adobe Premiere Pro plans to introduce third-party AI model functionality, enabling editors to choose the models that best suit their footage and enhancing the editing experience. These AI models include Sora from OpenAI, Runway AI's video models, and Pika's video models. Furthermore, Premiere Pro will offer content verification features to help users understand whether they have used AI and which model was used in their media creation.
AI Video Editing
130.3K
Xound.io
Xound is an AI-powered audio enhancement system that automatically cleans background noise, tunes pitch, and boosts audio quality, providing professional-level audio for creators on YouTube and TikTok. Utilizing advanced machine learning algorithms, the system can process audio files locally, ensuring data privacy and security. Key features include noise reduction, pitch correction, and audio enhancement, suitable for creators, podcast hosts, and YouTubers aiming to elevate the audio quality of their content to attract more viewers.
Audio Production
48.0K
Hanami Live Translator
Hanami Live Translator is a real-time translation tool that captures any audio from WINDOWS speakers and microphones. It utilizes lightweight multi-process and chunk processing of audio, with each chunk taking approximately 3-5 seconds to process. The application creates a hardware loopback via low-level access, allowing it to listen to content even when the speakers are muted. It uses the soundcard library to capture audio signals, the SpeechRecognition library to convert binary audio to text, and the selenium library to simulate network calls to deepl servers for free translation. The application requires an internet connection to operate and logs all actions through the Traces.log file.
AI Translation
124.8K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.8K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.5K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M